近日,我院李琳副教授团队在错误标签干扰下的声纹识别关键技术研究取得重要进展,相关成果以“When Speaker Recognition Meets Noisy Labels: Optimizations for Front-ends and Back-ends”为题发表于计算机语音领域国际顶级期刊《IEEE/ACM Transactions on Audio, Speech, and Language Processing》。
声纹识别是指从说话人的语音信号中提取声纹特征,并通过有效的分类识别模型,对说话人的身份进行校验和鉴别,其广泛应用于刑侦、人机交互口令验证等领域。当前的声纹识别系统通常包括两个模块:神经网络特征提取前端和概率线性判别分析(PLDA)后端。然而在现实中,训练数据错误标注问题不可避免。而矛盾在于:若想训练性能足够好的声纹识别系统,大量正确标注的数据是必要的,而另一方面,神经网络和PLDA往往会拟合噪声样本,从而导致模型偏离样本的真实标注,在实际应用中性能急剧下降。
在该工作中,李琳副教授团队首次系统地探究了错误标签对声纹识别系统的影响,并针对神经网络和后端分类器分别提出噪声标签干扰的优化方案。
针对神经网络,团队基于训练策略和损失函数两个方面进行优化,通过将网络预测标签引入到损失函数,提出了标签置信度学习策略,并结合后验概率权重调整技术和“子中心类”思想,进一步抑制错误标签的影响。针对后端分类器,团队采用变分贝叶斯PLDA建模方法实现对带噪标签训练集的PLDA模型参数估计,还可进一步筛选出训练集中带错误标签的样本。实验表明,通过前后端的联合优化,即使在训练数据标签错误率高达50%的情况下,系统也能稳定地训练,并获得准确的声纹判别结果。这为带噪标签声纹识别系统训练提供了一种解决策略,也为后续声纹识别系统利用无标签数据进行半监督学习提供了可行的研究思路,具有良好学术意义和应用前景。
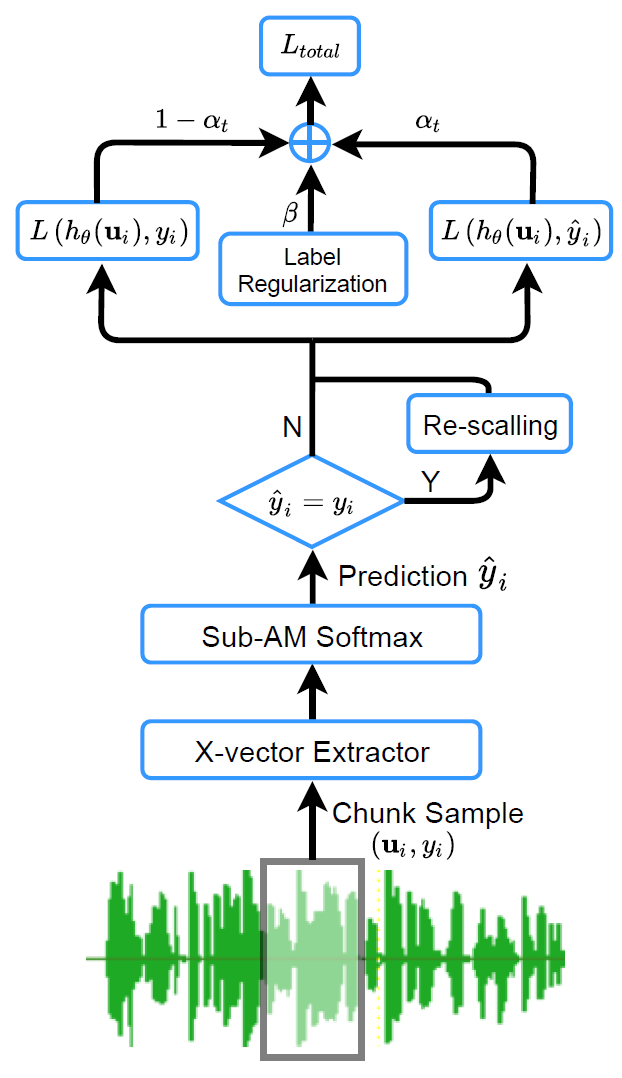
图示 前端神经网络优化
上述工作由银娱优越会717智能语音实验室独立完成,李琳副教授为第一作者,李琳副教授、信息学院洪青阳副教授为共同通讯作者。研究工作得到了国家自然科学基金(No. 61876160、No. 62001405)、中央高校基本科研基金(No. 20720210087)等科技计划资助。
原文链接:https://ieeexplore.ieee.org/document/9763412
(图文:李琳课题组)









